ROLLUP - ROLLUP (expression_list [, expression_list] ...)
expression_list = {expr [, expr] ... | ([expr [, expr]]...}
ROLLUP은 지정한 표현식의 계층별 소계와 총계를 집계.
| ROLLUP(a) | (a), () |
| ROLLUP(a, b) | (a, b), (a), () |
| ROLLUP(a, b, c) | (a, b, c), (a, b), (a), () |
expr을 뒤쪽부터 하나씩 제거하는 방식으로 결과에서 (a, b, c)는 a, b, c의 소계를 나타내며 ()는 총계를 의미.

deptno별 소계와 총계를 집계
SELECT deptno, COUNT(*) AS c1 FROM emp WHERE sal > 2000
GROUP BY ROLLUP(deptno) ORDER BY 1;
| DEPTNO | C1 | |
| 10 | 2 | deptno |
| 20 | 3 | deptno |
| 30 | 1 | deptno |
| 6 | () |
위의 표 처럼 그룹핑한 deptno를 뒤에서부터 제거하여 deptno를 마지막에 총계를 집계하여 보여준다.
deptno, job별 deptno별 소계와 총계를 집계
SELECT deptno, job, COUNT(*) AS c1 FROM emp WHERE sal > 2000
GROUP BY ROLLUP(deptno, job) ORDER BY 1, 2;

| DEPTNO | JOB | C1 | |
| 10 | MANAGER | 1 | deptno, job |
| 10 | PRESIDENT | 1 | deptno, job |
| 10 | 2 | deptno | |
| 20 | ANALYST | 2 | deptno, job |
| 20 | MANAGER | 1 | deptno, job |
| 20 | 3 | deptno | |
| 30 | MANAGER | 1 | deptno, job |
| 30 | 1 | deptno | |
| 6 | () |
위의 표 처럼 그룹핑한 deptno, job을 뒤에서부터 제거하여 deptno로 소계를 구하고 마지막에 전부 제거하여 총계를 집계하여 보여준다.
CUBE - CUBE (expression_list [, expression_list]...)
CUBE - 지정한 표현식의 모든 조합을 집계한다.
| CUBE(a) | (a), () |
| CUBE(a, b) | (a, b), (a), (b), () |
| CUBE(a, b, c) | (a, b, c), (a, b), (a, c), (b, c), (a), (b), (c), () |

SELECT deptno, COUNT(*) AS C1
FROM emp
WHERE sal > 2000
GROUP BY CUBE(deptno)
ORDER BY 1;
| DEPTNO | C1 | |
| 10 | 10 | deptno |
| 20 | 3 | deptno |
| 30 | 1 | deptno |
| 6 | () |
표현식이 하나면 ROLLUP과 결과가 동일.
표현식이 2개를 사용한 CUBE 쿼리.
SELECT deptno, job, COUNT(*) AS C1
FROM emp
WHERE sal > 2000
GROUP BY CUBE(deptno, job)
ORDER BY 1, 2;
| DEPTNO | JOB | C1 | |
| 10 | MANAGER | 1 | deptno, job |
| 10 | PRESIDENT | 1 | deptno, job |
| 10 | 2 | deptno, | |
| 20 | ANALYST | 2 | deptno, job |
| 20 | MANAGER | 1 | deptno, job |
| 20 | 3 | deptno | |
| 30 | MANAGER | 1 | deptno, job |
| 30 | 1 | deptno | |
| ANALYST | 2 | job | |
| MANAGER | 3 | job | |
| PRESIDENT | 1 | job | |
| 6 | () |
GROUPING SETS - GROUPING SETS({rollup_cube_clause | grouping_expression_list})
지정한 행 그룹으로 행을 집계한다. 행 그룹으로 ROLLUP과 CUBE를 사용할 수 있다.
| GROUPING SETS (a, b) | (a), (b) |
| GROUPING SETS ((a, b), a, ()) == ROULLUP (a, b) | (a, b), (a), () |
| GROUPING SETS (a, ROLLUP(b)) | (a), (b), () |
| GROUPING SETS (a, ROLLUP(b, c)) | (a), (b,c), (b), () |
| GROUPING SETS (a, b, ROLLUP(c)) | (a), (b), (c), () |
SELECT deptno, job, COUNT(*) AS C1
FROM emp
WHERE sal > 2000
GROUP BY GROUPING SETS (deptno, job)
ORDER BY 1, 2;
| DEPTNO | JOB | C1 | |
| 10 | 2 | deptno | |
| 20 | 3 | deptno | |
| 30 | 1 | deptno | |
| ANALYST | 2 | job | |
| MANAGER | 3 | job | |
| PRESIDENT | 1 | job |
GROUPING SETS에 ROLLUP
SELECT deptno, job, COUNT(*) AS C1
FROM emp
WHERE sal > 2000
GROUP BY GROUPING SETS (deptno, ROLLUP(job))
ORDER BY 1, 2;
| DEPTNO | JOB | C1 | |
| 10 | 2 | deptno | |
| 20 | 3 | deptno | |
| 30 | 1 | deptno | |
| ANALYST | 2 | job | |
| MANAGER | 3 | job | |
| PRESIDENT | 1 | job | |
| 6 | () |
조합 열 - 하나의 단위로 처리되는 열의 조합
| ROLLUP((a, b)) | (a, b), () |
| ROLLUP(a, (b, c)) | (a, b, c), (a), () |
| ROLLUP((a, b), c) | (a, b, c), (a, b), () |
SELECT deptno, job, COUNT(*) AS C1
FROM emp
WHERE sal > 2000
GROUP BY ROLLUP((deptno, job))
ORDER BY 1, 2;
| DEPTNO | JOB | C1 | |
| 10 | MANAGER | 1 | deptno, job |
| 10 | PRESIDENT | 1 | deptno, job |
| 20 | ANALYST | 2 | deptno, job |
| 20 | MANAGER | 1 | deptno, job |
| 30 | MANAGER | 1 | deptno, job |
| 6 | () |
SELECT deptno, job, empno, COUNT(*) AS C1
FROM emp
WHERE sal > 2000
GROUP BY ROLLUP(deptno, (job, empno))
ORDER BY 1, 2;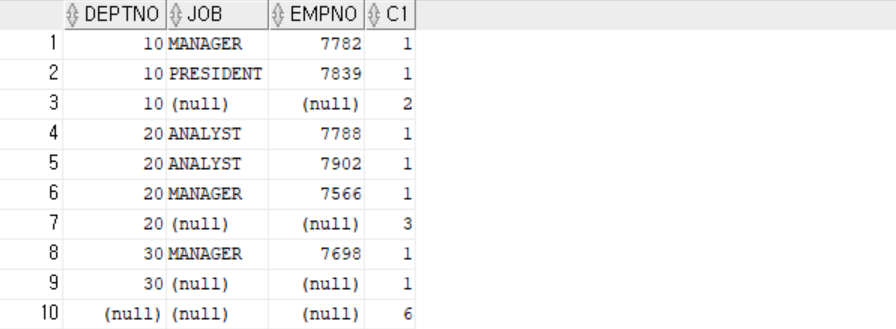
| DEPTNO | JOB | EMPNO | C1 | |
| 10 | MANAGER | 7782 | 1 | deptno, job, empno |
| 10 | PRESIDENT | 7839 | 1 | deptno, job, empno |
| 10 | 2 | deptno | ||
| 20 | ANALYST | 7788 | 1 | deptno, job, empno |
| 20 | ANALYST | 7902 | 1 | deptno, job, empno |
| 20 | MANAGER | 7566 | 1 | deptno, job, empno |
| 20 | 3 | deptno | ||
| 30 | MANAGER | 7698 | 1 | deptno, job, empno |
| 30 | 1 | deptno | ||
| 6 | () |
연결 그룹 - 행 그룹을 간결하게 작성할 수 있다.
| a, ROLLUP(b) | (a, b), (a) |
| a, ROLLUP(b, c) | (a, b, c), (a, b), (a) |
| a, ROLLUP(b), ROLLUP(c) | (a, b, c), (a, b), (a, c), (a) |
| GROUPING SETS(a, b), GROUPING SETS(c, d) | (a, c), (a, d), (b, c), (b, d) |
SELECT deptno, job, COUNT(*) AS C1
FROM emp
WHERE sal > 2000
GROUP BY deptno, ROLLUP(job)
ORDER BY 1, 2;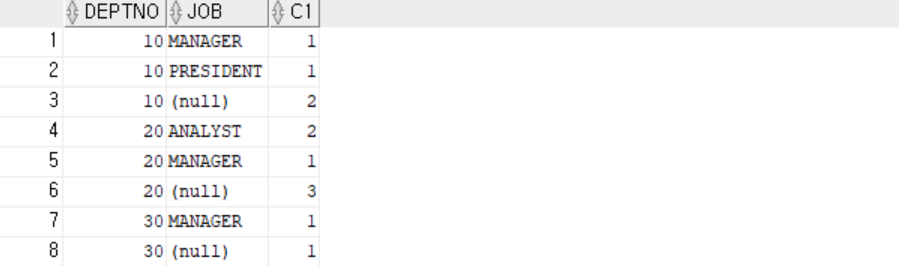
| DEPTNO | JOB | C1 | |
| 10 | MANAGER | 1 | deptno, job |
| 10 | PRESIDENT | 1 | deptno, job |
| 10 | 2 | deptno | |
| 20 | ANALYST | 2 | deptno, job |
| 20 | MANAGER | 1 | deptno, job |
| 20 | 3 | deptno | |
| 30 | MANAGER | 1 | deptno, job |
| 30 | 1 | deptno |
GROUPING 함수 - GROUPINg(expr)
expr이 행 그룹에 포함되면 0, 포함되지 않으면 1을 반환.
NULL로 반환되는 행 그룹에 값을 지정하거나 결과의 정렬 순서를 조정할 수 있음.
SELECT deptno, job, COUNT(*) AS C1, GROUPING(deptno) AS G1, GROUPING(job) AS G2
FROM emp WHERE sal > 2000 GROUP BY ROLLUP(deptno, job) ORDER BY 1, 2;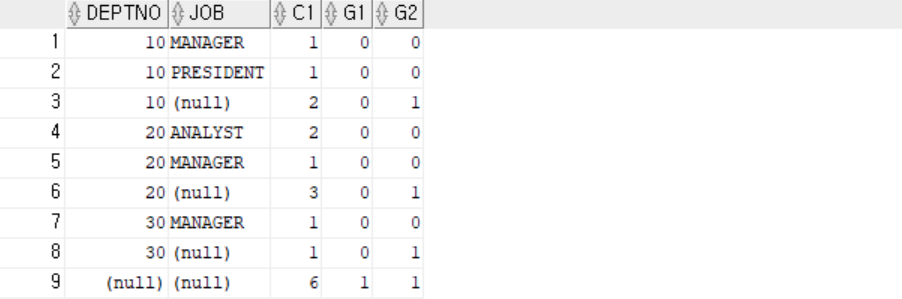
CASE 문을 이용해서 좀더 깔끔하게 수정 가능.
SELECT CASE WHEN GROUPING(deptno) = 1 AND GROUPING(job) = 1 THEN 'TOTAL'
ELSE TO_CHAR(deptno)
END AS deptno,
CASE WHEN GROUPING(deptno) = 0 AND GROUPING(job) = 1 THEN 'ALL'
ELSE TO_CHAR(job)
END AS job,
COUNT(*) AS C1, GROUPING(deptno) AS G1, GROUPING(job) AS G2
FROM emp WHERE sal > 2000 GROUP BY ROLLUP(deptno, job) ORDER BY 4, 5, 1, 2;
GROUPING_ID 함수 - GROUPING_ID (expr [, expr]...)
GROUPING 함수의 결과 값을 연결한 값의 비트 벡터에 해당하는 숫자 값을 반환
SELECT DECODE(GROUPING_ID(deptno, job), 3, 'TOTAL', TO_CHAR(deptno)) AS deptno,
DECODE(GROUPING_ID(deptno, job), 1, 'ALL', job) AS job,
COUNT(*) AS C1,
GROUPING(deptno) AS G1,
GROUPING(job) AS G2,
BIN_TO_NUM(GROUPING(deptno), GROUPING(job)) AS bn
FROM emp WHERE sal > 2000 GROUP BY ROLLUP(deptno, job) ORDER BY 6, 1, 2;
GROUP_ID 함수 - GROUP_ID ()
중복되지 않은 행 그룹은 0, 중복된 행 그룹은 1을 반환.
중복된 행 그룹을 제거할 때 사용
SELECT deptno, job, COUNT(*) AS C1, GROUP_ID() AS GI
FROM emp WHERE sal > 2000 GROUP BY deptno, ROLLUP(deptno, job);
| DEPTNO | JOB | C1 | GI | |
| 10 | MANAGER | 1 | 0 | deptno, deptno, job |
| 10 | PRESIDENT | 1 | 0 | deptno, deptno, job |
| 20 | ANALYST | 2 | 0 | deptno, deptno, job |
| 20 | MANAGER | 1 | 0 | deptno, deptno, job |
| 30 | MANAGER | 1 | 0 | deptno, deptno, job |
| 10 | 2 | 0 | deptno, deptno | |
| 20 | 3 | 0 | deptno, deptno | |
| 30 | 1 | 0 | deptno, deptno | |
| 10 | 2 | 1 | deptno | |
| 20 | 3 | 1 | deptno | |
| 30 | 1 | 1 | deptno |
'Develop > DATABASE' 카테고리의 다른 글
| 오라클)조인(join) - 조인 조건(카티션 곱, 등가 조인, 비등가 조인) (0) | 2022.12.28 |
|---|---|
| 오라클)HAVING 절 (0) | 2022.12.20 |
| 오라클)GROUP BY 절 - GROUP BY (0) | 2022.12.14 |
| 오라클)KEEP 키워드 - DENSE_RANK (FIRST | LAST) (0) | 2022.10.29 |
| 오라클)집계 함수 - 기타 (LISTAGG) (0) | 2022.10.29 |




댓글